分布式设计
- 1.复制
- 作用
- 对数据备份,实现高可用
- 提高吞吐量,实现高性能
- 分类
- 主从架构
- 性能
- 一主多从,读写分离,提高吞吐量
- 可用性
- 主库单点,一旦挂了,无法写入
- 从库高可用
- 一致性
- 数据同步存在延迟,读时从库中返回的可能是旧数据
- 解决方案
- 直接忽略,存在延迟很正常
- 班不同步复制(semi-sync),主从同步完成写请求才返回,吞吐量降低
- 选择读主
- 思路
- 写操作时,根据库+表+业务特征生成key设置到缓存中并设置超时时间(大于等于主从数据同步时间),读操作时,同样方式生成key,先去查缓存,如果命中则读主库,否则读从库
- 技术难点
- 主从数据同步时间的计算 不同网络,配置下,时间不一样
- 很多数据库的中间件就是使用的这种思路,如mycat等,但是中间件的成本同样不低
- 思路
- 对于即时性有要求的接口,直接从主数据库读
- 解决方案
- 读写分离的情况下,并发出现更新丢失问题
- 数据同步存在延迟,读时从库中返回的可能是旧数据
-
-
- 悲观锁
- 必须加载主数据库商,这样就不能做读写分离
- 乐观锁
- 可以
- update当前读,这样也不能做读写分离
- 有一致性要求的接口,无法读写分离,只能从主库中操作
- 悲观锁
-
- 性能
- 多主架构(互为备份)
- 性能
- 负载均衡
- 可用性
- 高可用
- 一致性
- 和主从架构一样
- 性能
- 主主从从
- 高性能
- 高可用
- 一致性
- 和主从一样
- 主备
- 主库提供读写服务,备库做故障转移用
- 性能一般
- 提高性能 设置缓存
- 高可用
- 无一致性问题
- 使用广泛 58和阿里云
- 主从架构
- mysql主从同步的原理
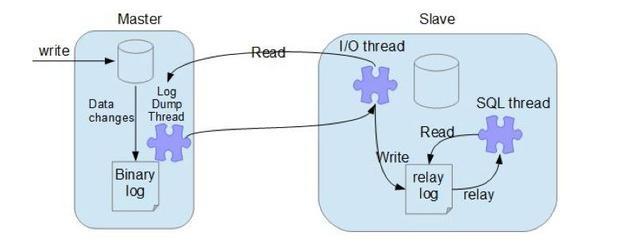
- 2.分片/分库分表
- 需求分析
- 用户请求量太大 -> 分布式服务器(分散请求到多个服务器上)
- 单库太大 单库所在服务器上磁盘空间不足;处理能力有限;出现IO瓶颈
- 单表太大 -> CRUD都成问题,索引膨胀,查询超时
- 作用
- 共同组成完整的数据集合,扩充单机存储的容量上限,读写速度上限
- 每个服务器节点成为分片
- 优点: 高吞吐
- 吞吐量越高,同一时间数据的读写完成量越高
- 一个节点可能单日吞吐量只能到达1TB(收硬件限制,硬盘速度有限)
- 垂直拆分
- 垂直分表
- 把字段分开成多张表
- 垂直分库
- 将有关联的表放在一个数据库中 如用户表,用户频道表等
- 项目处理
- 用户数据垂直分表 user_basic user_profile
- 文章数据垂直分表(文章内容较长且只在详情页才需要) article_basic article_content
- 两张表 定义时都包含其关联数据,这就要求使用事务来保证数据一致性
- 垂直分表
- 水平拆分
- 水平分表
- 将1000万条记录分成两张表
- 分表方式:按时间/id/地理/hash取模 分表
- 水平分库分表 分表分别放在不同的节点,使用率极高
- 分布式ID
- 需求:水平分表后,需要保证多表id不会出现冲突
- 解决方案
- UUID 通用唯一识别码 缺点:较长,不会趋势递增(主键如果不是递增的,索引效率会比较低)
- 数据库主键自增
- 方案1: 单独数据库 只负责生成主键 缺点:一旦宕机,全局瘫痪
- 方案2: 设置自增步长 所有表都使用相同的步长 缺点:分片规则不能修改,无法扩展
- Redis
- incr("user_id")返回的值自增
- 不会出现资源抢夺问题,因为redis是单线程的,可以保证原子性
- 缺点
- redis宕机
- redis易数据丢失
- 雪花算法-Snowflake
- twitter提出的算法,目的是生成一个64位的整数

- 缺点:时间回拨,及其的原因时间可能出现偏差,虽然会同步进行校正,但生成时可能是错误的
- 如果发生回拨(当前时间<记录的时间),算法会自动抛出异常,可以让用户稍等一会儿
- 取消同步ntp时间
- 项目中的应用
- 用户id 文章id 评论id 后期数据量可能会很大
- 前期数据量和请求次数少时,不要做分片
- 水平分表
- 分布式问题
- 一致性问题
- 主从延迟
- 对于即时性高的接口,直接从主库中提取
- 更新丢失
- 不进行读写分离,在主库中完成流程
- 主从延迟
- 分片id冲突
- 实现分布式ID
- 跨库原子性
- 一个业务中可能包含多个库中的写操作,该业务需要具有原子性,但是无不具备跨库原子性
- 解决办法
- 将有关联的表放在一个数据库中
- 使用分布式事务
- 核心是二阶段提交协议(简称 2PC协议/XA协议)
- 会出现事务等待的情况,增加死锁的产生机率,效率低
- 通过优化业务逻辑,实现基于消息的最终一致性方案(本质是通过消息队列执行异步任务,部分失败则不断重试/或全部取消,一般需要中间件完成任务分发,任务充实,消息幂等等)
- 分布式中间件 merge引擎 分库分表中间件 mycat
- 跨库join
- join不允许跨库完成
- 解决办法
- 分两次查询进行
- 开启FEDERATED引擎
- 跨库结果集 聚合/排序/分组
- 不允许跨库操作
- 分别查询,然后再应用端合并
- 项目中的处理
- 复制
- 采用了主从架构,实现了"手动读写分离",但没有对主从延迟进行特殊处理
- 分片
- 实现了垂直分表
- 使用了雪花算法生成了分布式ID,为水平分表提供了准备(单表行数至少超过1000万)
- 由于垂直分表后没有分库,所以没有(不需要)实现分布式事务(所有写操作都在一个主库中)
- 没有使用分布式中间件
- 复制
- 应用层设计方案
- 悲观锁
- 开发者主动设置锁
- 乐观锁
- 先不加锁(假设不会有并发问题),但是更新前校验数据一致性,需要手动代码实现
- Django项目中先判断库存,再生成订单,就是乐观锁设计
- 高级的乐观锁可能会采用版本号/时间戳来校验,需要进行表设计
-
1 读取点赞数,如like_count=102 每次更新表中的数据时,为了防止发生冲突,需要这样操作3 update t_article set like_count = 11 where article_id = 5 and like_count = 10;
- 悲观锁
- 一致性问题